工程效率对任何工程师团队的重要性都不言而喻:优秀的工程效率实践能够帮助团队更大程度发挥潜能,更高效地进行产品迭代;而低劣的工程效率模仿往往会让团队负重前行,每天都痛苦不堪,最终在沉默中燃尽所有的热情。
出于个人兴趣,我在每家公司都参与过工程效率相关的工作:在青云的时我推动了整条存储产品线 Golang 版本管理向 Go Modules 的迁移,在参与 Databend 的过程中我重新设计了全新的 CI/CD Pipeline,完成了从自行部署的 fusebot 到完全 SaaS 化的 PR 流程迁移。今天这篇文章主要总结了我在 Databend 的工程效率实践,首先介绍 Databend 的具体实践,然后再聊聊我个人的一些心得体会,希望对其他开源项目的相关实践落地能够有所帮助。
Databend 没有专职的工程效率团队,相关实践能够落地需要感谢 @everpcpc, @ZeaLoVe 和 @PsiACE 等同学在本职工作之外的付出。
Databend 的工程效率实践
Databend 是一个由 Rust 开发的开源云上数据仓库,在过去的一个月中,活跃贡献者超过 30 位,平均每天有 10 个 PR 被合并。当社区中充满了才华横溢的贡献者,保障他们的想法成功落地,而不是让热情消耗在无尽的测试重试中就就异常重要。不仅如此,对开源社区来说,工程效率格外具有现实意义:每个 PR 的 CI 时间和合并速度都被所有人看在眼里。潜在的贡献者被动辄数小时的 CI 时长劝退,或者更糟糕一点,现有的贡献者被复杂的流程逼迫着放弃了贡献,是对开源共同体建设的重大打击。
Databend 社区尝试从以下层面解决这些问题:
- 无感流程
- 靠谱 CI
无感流程
最好的流程是没有流程,更确切的说,是无感知的流程:贡献者凭直觉就能够顺畅地进行贡献。
Databend 在引入流程时会努力避免对贡献者的打扰,尽可能做到流程正常的时候什么都不用操心,而流程出错时,贡献者可以得到信息充分且友好,足以自行解决的错误提示。
以语义化 PR 为例,如果 PR 的标题不符合规范,贡献者将得到这样的反馈:
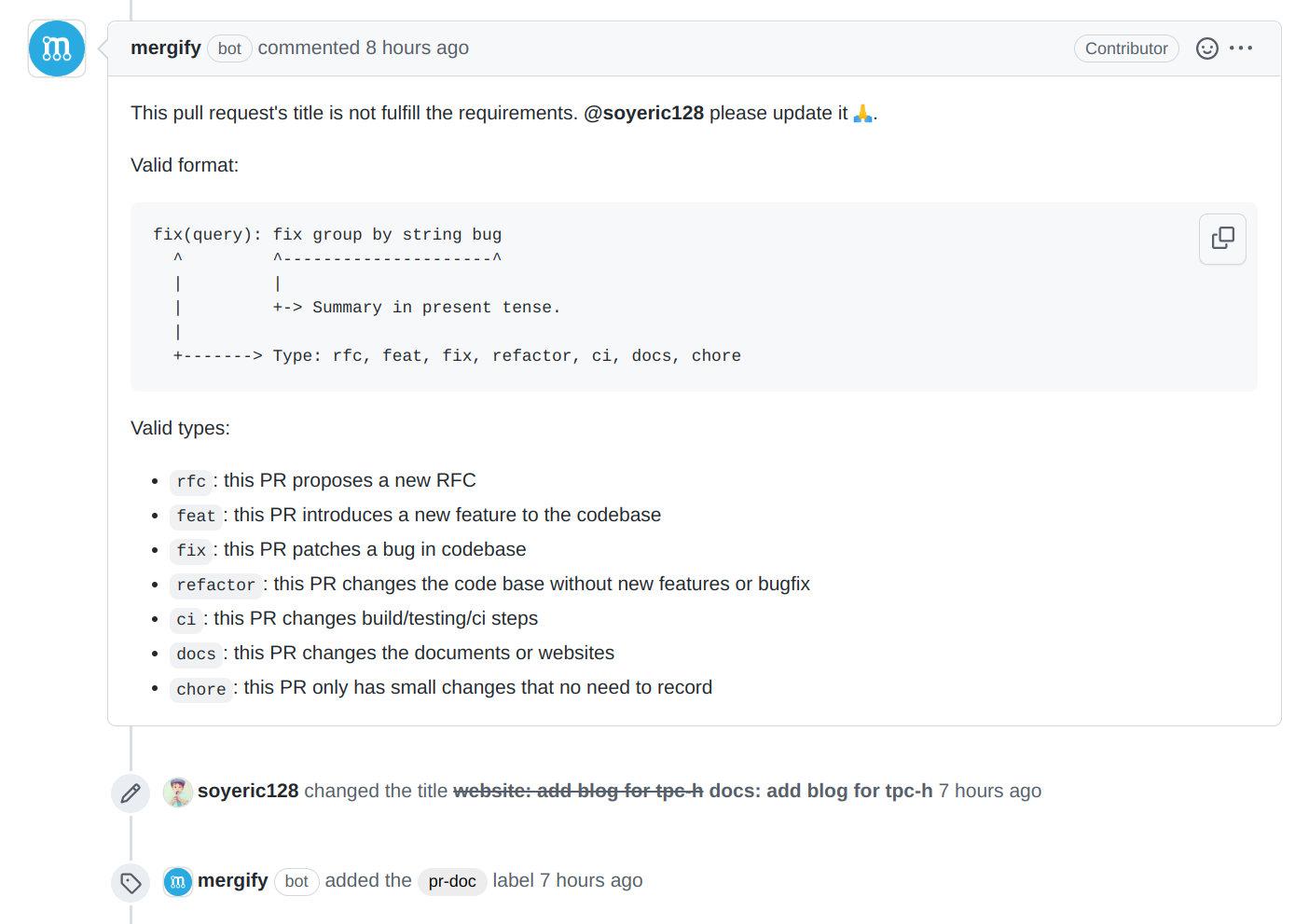
这样做的好处在于贡献者可以凭直觉提交 PR,不需要事先朗读并背诵开发者文档。如果 PR 满足要求,等待 Review;如果 PR 不满足,根据评论给出的信息可以自行修改,下一次 PR 时就知道了应该如何去做。即使忘记了也没有关系,我们的 bot 仍然会友好的再次给出同样的信息。如此往复多次,一个熟练的贡献者就诞生了。这个过程中不需要人工介入,可以减少维护者的精力损耗,避免维护者一再要求开发者修改低级的格式问题,从侧面提升了维护者的 Review 质量。
除了流程本身的设计外,流程持续的维护也很重要。
过去 Databend 使用自己开发的 fusebots 来维护自定义的流程,遇到的问题有:
- 后续维护力量不足:fusebots 最开始由 BohuTANG 开发并维护,但随着开发重心的偏移,BohuTANG 已经不再专注于 fusebots 的开发,同时未来的发展也没有清晰的规划。
- 社区采用率低:fusebots 被设计用来解决 databend 的特定流程问题,缺乏复用迁移的价值,其他社区很难采用推广该方案,这进一步影响了 fusebots 未来的存续
- 自行部署运维:fusebots 在实现上是一个监听 Events 并进行相应处理的 server,不提供在线的 SaaS 服务,要求用户自行部署并维护。使用者不知道 fusebots 当前的状态,出了问题之后必须由运维调试并查看。
- 不满足无感要求:fusebots 要求用户使用命令来触发,不满足我们对无感流程的期望
后来 Databend 转向采用 Mergify 进行 PR 自动化管理,目前已经应用的规则包括:
- 贡献者的 PR 标题需要符合语义化要求,否则在 PR Checks 中报错,通过评论的方式反馈并要求修改
- 贡献者的 PR 描述需要符合规范,不符合规范则在 PR Checks 中报错,通过评论的方式反馈并要求修改
- 根据贡献者不同的 PR 类别,会运行不同的 Checks,最终的合并要求也不一样:
- 代码贡献需要两个 Approval,并通过所有的测试用例
- 文档贡献则只需要一个 Approval 以及 Vercel 构建成功即可
靠谱 CI
CI 是现代开源项目的标配,在 2022-30: 如何维护一个开源项目 中我强调过 CI 对开源项目的重要性:
开源维护者必须维护一个良好的集成测试基础设施:在开源协作的环境下,不可能有一个测试团队来为所有 PR 运行测试,因此社区需要一个持续的集成测试服务来保证所有的 PR 都通过必要的测试再合并。
靠谱 CI 的含义是多重的:CI Infra 本身必须要靠谱,不会频繁因为基础设施本身的问题出现故障;CI Pipelines 语法及其执行必须靠谱,有充足的文档供参考,其行为可测试可预测。
Databend 目前的 CI 已经全部收敛到 Github Actions,其中 PR 相关的测试由 Databend Cloud 赞助并维护的 Self-hosted Runner 执行,而 Main 分支上的测试则由 Github-hosted Runner 执行。这是成本和效率的综合考量:社区更关心 PR 的 CI 完成效率,而 main 分支上的测试只要能够正常执行完毕即可。
Databend Cloud 在测试环境部署了支持弹性扩缩容的 Self-hosted Runner Operator:每当 Databend 有 PR 需要执行构建时会优先寻找当前活跃的 Runner,否则就立即启动一个新的。经过 @everpcpc 多轮尝试和调优,Databend 现在的 runner 配置是这样:
- 每次启动一个 16C32G 的 Spot VM,上面运行两个 Runner 容器
- 每个容器会请求 7.5C12G 的资源,设定的最大限制是 12C15G
- 此外,每个 VM 会配置一个 80G 的 EBS
这样的配置同样在成本和效率中取得了平衡:目前 Databend 的 PR 合并必须的测试基本都能在 20 分钟内完成,其中包括所有的静态检查,x86_64/aarch 两种架构,gnu/musl 两种 libc 依赖,还有全部的逻辑测试,无状态测试,有状态测试等。
Datafuse Labs 创立之初就计划要做 Data Cloud SaaS 服务,所以非常理解 SaaS 的价值,在各项工具的采购上都积极拥抱 SaaS。其实这也很好理解:对 Databend 来说,它的核心价值就在于做好 Data Cloud SaaS,其他的产品都是为了这个目标服务的。维护一套自己的 CI 服务对 Databend 团队的核心目标没有任何贡献,反而需要一个专门的团队来持续投入和维护,这是不划算的。在调研了市场上多个 SaaS 服务后,Databend 最后选择了现在的方案:一方面 Databend 有着自己完整的 K8s 技术栈,增加了一个 Self-hosted Runner 的维护负担很小;另一方面完全托管的 CI SaaS 服务非常昂贵,比自己的 self-hosted runner 要贵的多。
在实践上,Databend 会尽可能使用 AWS 内网中的服务来优化成本:
- 将 CI 过程中产生的构建产物放在内部一个专门的 S3 上并配置自动删除的生命周期,这样 runner 上传和下载都是免流量费用的
- 使用 AWS 自带的容器镜像服务,在内网使用无需公网流量费
- 实现资源隔离,避免 Github-hosted Runner 访问内部的服务,比如 Github-hosted Runner 使用 Dockerhub 而不是 AWS 的容器镜像
总的来说,Github Actions + Self-hosted CI 并配合一些成本优化策略是一个非常不错的实践。
Xuanwo 的工程效率体会
根据我在 Databend 的实践,我有这样的一些体会:
- 摆正定位
- 渐进变更
- 公开透明
摆正定位
从事工程效率方面的工作首先要摆正自己的定位:工程效率是为加速产品交付效率服务的。切不可本末倒置,盲目的增加累赘的审批流程,生成没人看的报表,落入形式主义的窠臼。在开源社区中落地工程效率尤其需要注意赋能而不是控制:为贡献者提供足够的信息帮助他解决问题,而不是给出各种生硬的报错来命令贡献者按照自己的意愿行事。设计流程和对 CI 做调整时要从社区的实际感受出发,跟社区第一线的贡献者广泛沟通然后再做出调整。
渐进变更
对流程做调整要少量多次,每次慢慢调整,给社区一些调整和适应的时间。新的流程上线之后可以跟社区沟通一下,听听最直接的反馈,对流程予以优化或者直接回退。
公开透明
对开源项目来说,工程效率的改进往往是自下而上的:在第一线的工程师通常对工程效率有最深刻的体会,他们有意愿改进自己的工作体验。所以不管是流程还是 CI 最好都能够做到公开透明,允许社区的同学提出自己的改进意见。采用一个现成的,已经被广泛使用的 CI Services 同样有助于贡献者迁移自己来自其他社区的经验。比如 Databend 使用 Github Actions,有多位贡献者提交 PR 来应用其他项目中的最佳实践。如果我们用的是 Jenkinsfile,相信很难得到类似的反馈。
总结
这篇文章总结了 Databend 的工程效率实践和我个人一些心得体会,欢迎大家在评论区跟我交流~