Iteration 12 从 4/23 开始到 5/6 结束,为期两周。这个周期成功走出了自己的舒适圈,探索了不少之前自己从未了解的东西,比如 tree-sitter,parser,hdfs,java 等等,感觉收获非常多。最近反复读了很多遍 @mitchellh 写的 Contributing to Complex Projects,今天这份周报就结合自己从零开始参与贡献 difftastic 的经历来介绍如何贡献复杂的项目。
前言
Contributing to Complex Projects 文章中将贡献复杂项目分解为如下几步:
- Step 1: Become a User,成为用户
- Step 2: Build the Project,构建项目
- Step 3: Learn the Hot-Path Internals,学习内部的关键逻辑
- Step 4: Read and Reimplement Recent Commits,阅读并重新实现最近的 commits
- Step 5: Make a Bite-sized Change,做一个小变更
这些步骤适用于绝大多数项目,不过需要根据个人的偏好和实际情况做一些调整。比如我更倾向于做一些能最终合并到主干的事情,所以我参与贡献的过程中往往会略过这里的 Step 4 并直接尝试实现一些相对容易的 feature。大家在参与贡献的过程也需要视情况调整自己的策略,不要教条式地照搬这里的步骤。
关于 difftastic
difftastic 是一个使用 Rust 开发的能理解语义的 diff 工具。
它能够理解我们在代码中修改的字符是数组的 Item 还是函数的参数,以 Javascripts 为例:
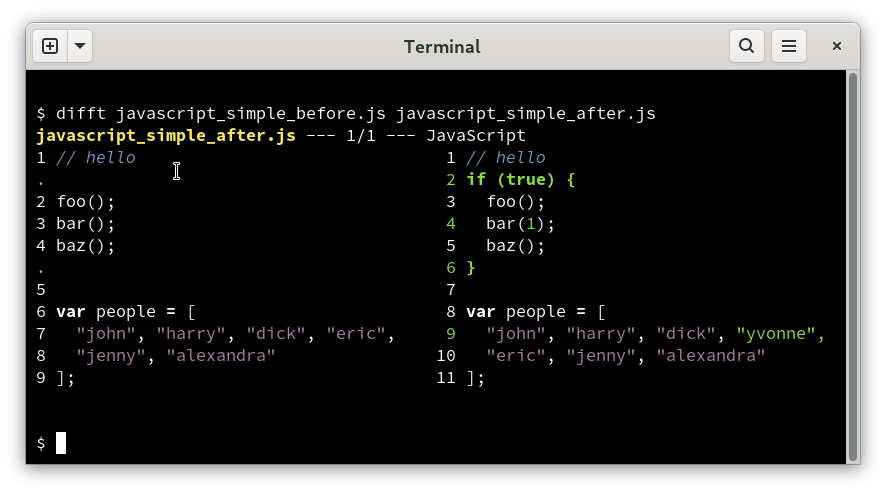
- 高亮了
{,}但是这里的foo();并没有修改,尽管 indent 变了,因为它理解嵌套 - 将左边的
bar()和右边的bar(1)对齐,因为它知道他们是同一个 function call。 - 这里的
eric被移动到了下一行,但是并没有被高亮出来,因为它知道这是一个不改变语义的换行。
在背后,difftastic 使用 tree-sitter 来解析并对比文件的 AST,而不是基于纯字符的差异对比。
目前 difftastic 支持 30 多种编程语言和配置文件的 diff,并能够运行在 Linux,MacOS,Windows 等主流平台上。
成为用户
开源项目非常有趣的一点就在于:开发者往往是用户本身。
Arch 之道中的 User centrality 原则指出:
许多 Linux 发行版都试图变得更“用户友好”,Arch Linux 则一直是,永远会是“以用户为中心”。此发行版是为了满足贡献者的需求,而不是为了吸引尽可能多的用户。Arch 适用于乐于自己动手的用户,他们愿意花时间阅读文档,解决自己的问题。
我认为这才是参与开源最重要的一步。成为用户,去使用它,去理解它是做什么的,去主动发现不足和改进点,而不是一上来就抱着长长的设计文档啃。很多同学的开源热情往往就消磨在漫长的文档阅读过程中:我们并不需要成为这个方面的专家才能参与项目的贡献。在贡献 difftastic 之前,我对 parser,tree-sitter 一无所知。即使是现在,我也对他们的了解也只局限于他们是做什么的,并不知道他们究竟如何工作,更别提阅读他们的代码了。但是这并不妨碍我为 difftastic 贡献了多种语言的支持,并修复若干个引起 Crash 的 BUG。
绝大多数开源项目都会提供安装和使用的文档,difftastic 也不例外。我参考 Installation 和 Usage 中成功安装并配置好了 difftastic。我很快发现 difftastic 缺少对 perl 和 hcl 的支持,于是决定为它加上。
构建项目
参与开源项目的第二步是部署开发环境并进行成功的构建。difftastic 是一个纯 Rust 的项目,相关的依赖比较少,使用 cargo build 即可编译。
而复杂的项目往往会有着复杂的依赖,有些是项目必须的依赖,包括语言的构建工具,依赖管理,编译时工具等等,有些是项目开发过程中需要用到的工具,比如静态检查,代码格式化,集成测试等等。维护质量比较好的项目往往会提供 Contributing 或者 Get Started 文档来告知我们如何构建项目,比如 TiDB 在 TiDB Development Guide: Get Started 中详细介绍了编译 TiDB 需要依赖和步骤。更进一步的,有的项目会提供一个一键式脚本(尽管我并不喜欢这种)来处理依赖问题,比如 Databend 提供了 dev_setup.sh。像 Rust 这样开发环境配置高度复杂的项目还会开发额外的工具来自动化这些步骤。
作为开发者,我们需要做到的事情是完整的阅读 README 并寻找类似的信息。如果没找到的话可以尝试约定俗成的方式,比如项目下有 Makefile,package.json,Cargo.toml,go.mod 这些标志性的文件,我们可以直接尝试使用对应的命令。在成功构建后,我们可以尝试为项目提交一个修改 README 并增加构建步骤的文档以方便后来的同学。
学习关键路径
参与开源项目的第三步是学习关键路径。@mitchellh 将自己的方法概括为:trace down, learn up.:
当学习某个特性时:
- 首先自顶向下的寻找涉及到这个特性的 codepath 并忽略与之无关的细节
- 然后自底向上的学习这个子系统是如何工作的
- 尝试去修改代码,增加新的 log,增加简单的逻辑,修改某处细节,去理解为什么不工作了
- 阅读与这个特性有关的文档或者分享
不难发现,我们日常的学习和工作中往往也是如此,只是我们需要系统的运用到开源项目中。项目中的代码分布往往也遵循二八定律:20% 的代码实现了 80% 的功能,所以我们没有必要尝试理解项目中每一行代码的细节。最好的方式是带着问题来阅读代码,只寻找跟自己实现功能有关的逻辑。维护良好的开源项目往往会为核心的逻辑和模块添加细致的文档来解决常见的疑问,很多时候看文档就能解决我们的问题。
difftastic 就是如此,作者非常棒地提供了 Adding A Parser 的文档。在文档的帮助下,我只需要按照步骤依次执行并解决简单的编译问题即可。当然,更多的时候我们会面临文档的缺失和不足,这时候我们在理解这一模块后为项目贡献这份文档。就算理解错误也没有关系,在提交 PR 时我们可以跟作者进行讨论和确认,一方面能够帮助到有相同问题的贡献者,另一方面也能加深自己的理解和认识。
从小变更做起
参与开源的第四步是从小变更做起。贡献文档就是很好的开始,这能够帮助我们理解这个项目是如何进行讨论和开发的。
请尽量避免上来就承担特别复杂的任务,一方面我们需要通过贡献来积累自己在社区的声誉,另一方面复杂任务中途夭折会极大地打击自己的信心。比较推荐的方式是从比较小的功能做起,最好能够把影响局限在当前的子系统。伴随着我们实现功能,我们就能够从当前模块出发,去理解更多的模块如何共同工作。随着了解的模块增多,我们能够发现更多可以改进的点,参与到项目的持续演进中去。
在 fix: Remove trailing lines before calculating max_lines 中,我通过增加一些简单的 println 发现了问题的根源在 LineNumber 计算有误,从而给出了一个 fix:
- (max(1, self.as_ref().split('\n').count()) - 1).into()
+ (max(1, self.as_ref().trim_end().split('\n').count()) - 1).into()
但是很快我发现这行代码有些难以理解,所以我进行了简单的重构:
- (max(1, self.as_ref().trim_end().split('\n').count()) - 1).into()
+ self.as_ref()
+ .trim_end() // Remove extra trailing whitespaces.
+ .split('\n') // Split by `\n` to calculate lines.
+ .count()
+ .sub(1) // Sub 1 to make zero-indexed LineNumber
+ .into()
上述的变更都没有修改到别的模块,因此我只需要增加一个独立的单元测试即可,而作者能够快速的验证我的思路是否正确,避免了在 PR 中进行来回的讨论拉锯。
总结
贡献复杂的开源项目并不困难,掌握正确的方法论,我们都能够加入到开源的行列中来:
- 成为用户
- 构建项目
- 学习关键路径
- 从小变更做起
欢迎加入开源社区~