随着 Apache OpenDAL™ 社区的不断发展,新的抽象在不断增加,为新的贡献者参与开发带来了不少负担,不少维护者都希望对 OpenDAL 的内部实现有更深入的了解。与此同时,OpenDAL 的核心设计已经很长时间没有大幅度的变化,为写一个内部实现系列提供了可能。我想现在是时候写一系列关于 OpenDAL 内部实现的文章,从维护者的角度来阐述 OpenDAL 如何设计,如何实现以及如何扩展。在 OpenDAL v0.40 即将发布之际,希望这系列文章能够更好的帮助社区理解过去,掌握现在,并确定未来。
第一篇文章会先聊聊 OpenDAL 最常使用的数据读取功能,我会从最外层的接口开始,然后按照 OpenDAL 的调用顺序来逐步展开。让我们开始吧!
整体框架
在开始介绍具体的 OpenDAL 接口之前,我们首先熟悉一下 OpenDAL 项目。
OpenDAL 是一个 Apache Incubator 项目,旨在帮助用户从各种存储服务中以统一的方式便捷高效访问数据。它的项目愿景是 “自由访问数据”:
- Free from services: 任意服务都能通过原生接口自由访问
- Free from implementations: 无论底层实现如何,都可以通过统一的方式调用
- Free to integrate: 能够自由地与各种服务,语言集成
- Free to zero cost: 用户不需要为用不到的功能付出开销
在这套理念的基础上,OpenDAL Rust Core 可以主要分成以下组成部分:
- Operator: 对用户暴露的外层接口
- Layers: 不同中间件的具体实现
- Services: 不同服务的具体实现
所以从宏观的角度上来看,OpenDAL 的数据读取调用栈看起来会像是这样:
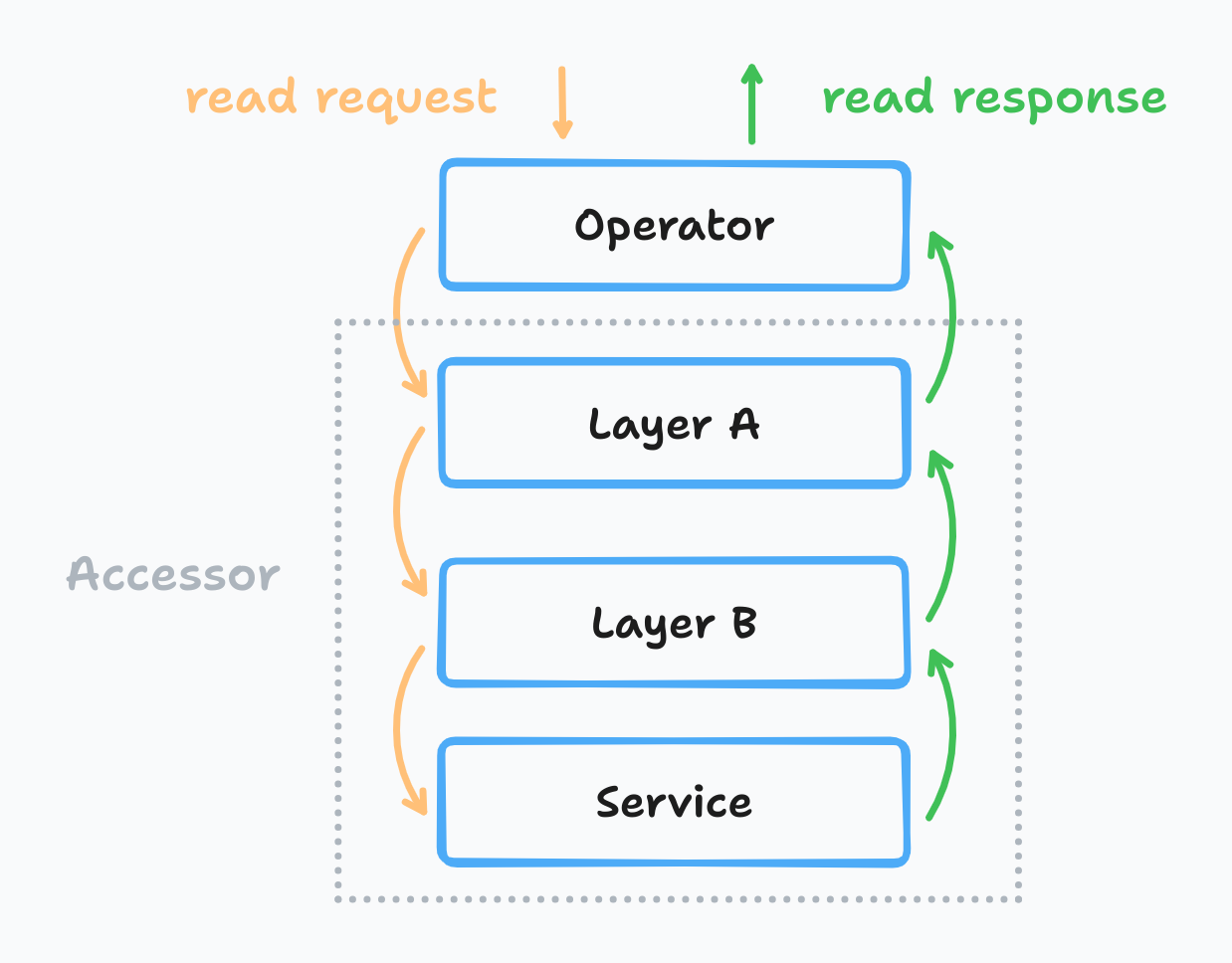
所有 Layers 和 Services 都实现了统一了 Accessor 接口,在进行 Operator 构建时会抹除所有的类型信息。对 Operator 来说,不管用户使用什么服务或者增加了多少中间件,所有的调用逻辑都是一致的。这一设计将 OpenDAL 的 API 拆分成了 Public API 和 Raw API 两层,其中 Public API 直接暴露给用户,提供便于使用的上层接口,而 Raw API 则是面向 OpenDAL 内部开发者提供,维护统一的内部接口,并提供一些便利的实现。
Operator
OpenDAL 的 Operator API 会尽可能遵循一致的调用范式,减少用户的学习和使用成本。以 read 为例,OpenDAL 提供了以下 API:
op.read(path): 将指定文件全部内容读出op.reader(path): 创建一个 Reader 用来做流式读取op.read_with(path).range(1..1024): 使用指定参数来读取文件内容,比如说 rangeop.reader_with(path).range(1..1024): 使用指定参数来创建 Reader 做流式读取
不难看出 read 更像是一个语法糖,用来方便用户快速地进行文件读取而不需要考虑 AsyncRead 等各种 trait。而 reader 则给予了用户更多的灵活度,实现了 AsyncSeek,AsyncRead 等社区广泛使用的 trait,允许用户更灵活的读取数据。read_with 和 reader_with 则通过 Future Builder 系列函数,帮助用户以更自然的方式来指定各种参数。
Operator 内部的逻辑看起来会是这样:
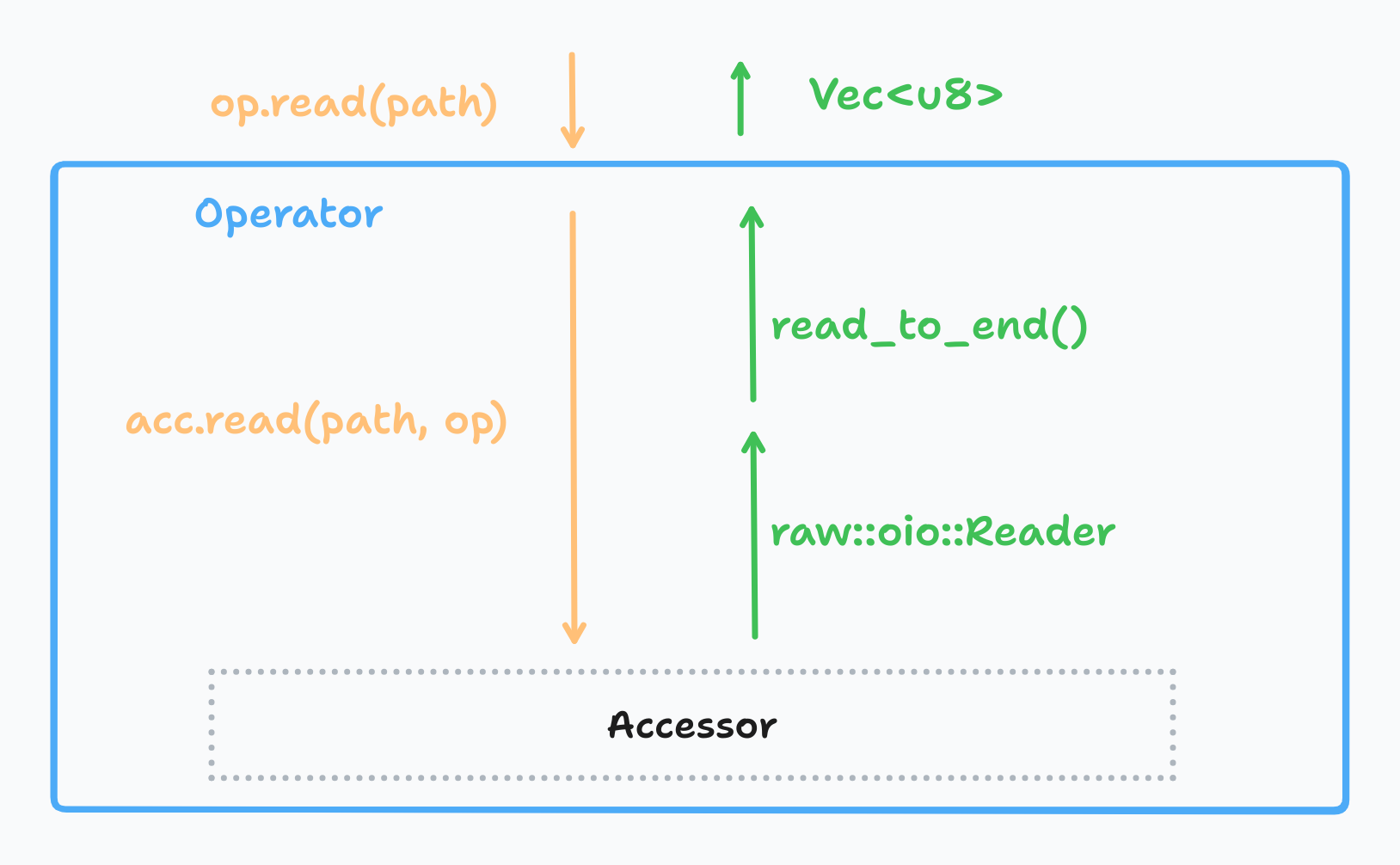
它的主要工作是面向用户封装接口:
- 完成
OpRead的构建 - 调用
Accessor提供的read函数 - 将返回的值包裹为
Reader并在Reader的基础上实现AsyncSeek,AsyncRead等接口
Layers
这里有一个隐藏的小秘密是 OpenDAL 会自动为 Service 套上一些 Layer 以实现一些内部逻辑,截止到本文完成的时候,OpenDAL 自动增加的 Layer 包括:
ErrorContextLayer: 为所有的 Operation 返回的 error 注入 context 信息,比如scheme,path等CompleteLayer: 为服务补全必须的能力,比如说为 s3 增加 seek 支持TypeEraseLayer: 实现类型擦除,将Accessor中的关联类型统一擦除,让用户使用时不需要携带泛型参数
这里的 ErrorContextLayer 和 TypeEraseLayer 都比较简单不再赘述,重点聊聊 CompleteLayer,它旨在以零开销的方式为 OpenDAL 返回的 Reader 增加 seek 或者 next 支持,让用户不需要再重复实现。OpenDAL 在早期版本中通过不同的函数调用来返回 Reader 和 SeekableReader,但是用户的实际反馈并不是很好,几乎所有用户都在使用 SeekableReader。因此后续 OpenDAL 在重构中将 seek 支持作为第一优先级加入了内部的 Read trait 中:
pub trait Read: Unpin + Send + Sync {
/// Read bytes asynchronously.
fn poll_read(&mut self, cx: &mut Context<'_>, buf: &mut [u8]) -> Poll<Result<usize>>;
/// Seek asynchronously.
///
/// Returns `Unsupported` error if underlying reader doesn't support seek.
fn poll_seek(&mut self, cx: &mut Context<'_>, pos: io::SeekFrom) -> Poll<Result<u64>>;
/// Stream [`Bytes`] from underlying reader.
///
/// Returns `Unsupported` error if underlying reader doesn't support stream.
///
/// This API exists for avoiding bytes copying inside async runtime.
/// Users can poll bytes from underlying reader and decide when to
/// read/consume them.
fn poll_next(&mut self, cx: &mut Context<'_>) -> Poll<Option<Result<Bytes>>>;
}
在 OpenDAL 中实现一个服务的读取能力就需要实现这个 trait,这是一个内部接口,不会直接暴露给用户,其中:
poll_read是最基础的要求,所有服务都必须实现这一接口。- 当服务原生支持
seek时,可以实现poll_seek,OpenDAL 会进行正确的 dispatch,比如说 local fs; - 而当服务原生支持
next,即返回流式的 Bytes 时,可以实现poll_next,比如说基于 HTTP 的服务,他们底层是一个 TCP Stream,hyper 会将其封装为一个 bytes stream。
通过 Read trait,OpenDAL 确保所有服务都能尽可能地暴露自己的原生支持能力,从而提供对不同服务都能实现高效的读取。
在此 trait 的基础上,OpenDAL 会根据各个服务支持的能力来进行补全:
- seek/next 都支持:直接返回
- 不支持 next: 使用
StreamableReader进行封装以模拟 next 支持 - 不支持 seek: 使用
ByRangeSeekableReader进行封装以模拟 seek 支持 - seek/next 均不支持:同时进行两种封装
ByRangeSeekableReader主要利用了服务支持 range read 的能力,当用户进行 seek 的时候就 drop 当前 reader 并在指定的位置发起新的请求。
OpenDAL 通过 CompleteLayer 暴露出一个统一的 Reader 实现,用户不需要考虑底层服务是否支持 seek,OpenDAL 总是会选择最优的方式来发起请求。
Services
经过 Layers 的补全之后,就到调用 Service 具体实现的地方,这里分别以最常见的两类服务 fs 和 s3 来举例说明数据是如何读取的。
Service fs
tokio::fs::File 实现了 tokio::AsyncRead 和 tokio::AsyncSeek,通过使用 async_compat::Compat,我们将其转化为了 futures::AsyncRead 和 futures::AsyncSeek。在此基础上,我们提供了内置的函数 oio::into_read_from_file 将其转化为实现了 oio::Read 的类型,最终的类型名为:oio::FromFileReader<Compat<tokio::fs::File>>。
oio::into_read_from_file 实现中没有什么特别复杂的地方,read 和 seek 基本上都是在调用传入的 File 类型提供的函数。比较麻烦的地方是关于 seek 和 range 的正确处理:seek 到 range 右侧是允许的行为,此时不会报错,read 也只会返回空,但是 seek 到 range 左侧是非法行为,Reader 必须返回 InvalidInput 以便于上层正确处理。
有趣的历史:当初这块实现的时候有问题,还是在 fuzz 测试中发现的。
Services s3
S3 是一个基于 HTTP 的服务,opendal 提供了大量基于 HTTP 的封装以帮助开发者重用逻辑,只需要构建请求,并返回构造好的 Body 即可。OpenDAL Raw API 封装了一套基于 reqwest 的接口,HTTP GET 接口会返回一个 Response<IncomingAsyncBody>:
/// IncomingAsyncBody carries the content returned by remote servers.
pub struct IncomingAsyncBody {
/// # TODO
///
/// hyper returns `impl Stream<Item = crate::Result<Bytes>>` but we can't
/// write the types in stable. So we will box here.
///
/// After [TAIT](https://rust-lang.github.io/rfcs/2515-type_alias_impl_trait.html)
/// has been stable, we can change `IncomingAsyncBody` into `IncomingAsyncBody<S>`.
inner: oio::Streamer,
size: Option<u64>,
consumed: u64,
chunk: Option<Bytes>,
}
这个 body 内部包含的 stream 是 reqwest 返回的 bytes stream,opendal 在此基础上实现了 content length 检查和 read 支持。
这里额外提一嘴关于 reqwest/hyper 的小坑:reqwets 和 hyper 并没有检查返回的 content length,所以一个非法的 server 可能会返回与预期的 content length 不符的数据量而非报错,进而导致数据的行为不符合预期。OpenDAL 在这里专门增加了检查,在数据不足时返回 ContentIncomplete,并在数据超出预期时返回 ContentTruncated,避免用户收到非法的数据。
总结
本文自顶向下介绍了 OpenDAL 如何实现数据读取:
- Operator 负责对用户暴露易用的接口
- Layers 负责对服务的能力进行补全
- Services 负责不同服务的具体实现
在整个链路中 OpenDAL 都尽可能遵循零开销的原则,优先使用服务原生提供能力,其次再考虑通过其他的方法进行模拟,最后才会返回不支持的报错。通过这三层的设计,用户不需要了解底层服务的细节,也不需要接入不同服务的 SDK 就可以轻松地调用 op.read(path) 来访问任意存储服务中的数据。
这就是: How OpenDAL read data freely!