介绍
今天要介绍的论文是 IPFS - Content Addressed, Versioned, P2P File System。
- 发表于 2014 年
- 作者是 Juan Benet
- 下载链接
这篇论文实际上是 IPFS 项目的白皮书,但是遵循鸭子原则,它看起来像是一片论文,我们就当作论文来读它。
IPFS 是 The InterPlanetary File System 的缩写,直译过来是 星际文件系统。作者想要设计出一个分布式文件系统来连接所有的计算设备,他们共享同一个命名空间,能够进行 P2P 传输,最终构建出一个永久性网络来取代现在的 HTTP。
假设
IPFS 白皮书中用这样几个短句概括了 IPFS 的设计:
- IPFS is peer-to-peer; no nodes are privileged.
- IPFS nodes store IPFS objects in local storage.
- Nodes connect to each other and transfer objects.
- These objects represent files and other data structures.
在我看来最核心的一点是:IPFS is peer-to-peer (P2P)。P2P 隐含着这样几个假设:
- 节点是不可靠的,节点会随时加入/退出
- 节点是不可信的,节点可能会作弊,捣乱,不守规矩
- 节点的网络是不稳定的
- 节点的数量可能会很大
- 不能依赖中心化的组件
我们会看到,这些假设深刻的影响了 IPFS 各个模块的设计。
概念
为了能构建出 P2P 的文件系统,IPFS 协议提出了以下几个子协议:
- Identities
- Network
- Routing
- Exchange
- Objects
- Files
- Naming
Identities
在传统的系统中,各个节点是可信的,节点不需要对来自内部节点的请求做额外的校验。在 Zero Trust 观念盛行的今天,大家会倾向于不自动信任内部的节点,转而使用静态密钥在连接时验证或者配置 TLS 证书对所有的请求进行加密。
但是这些方案并不适用于 P2P 的网络:
- 所有节点都配置有效的 TLS 证书并进行验证成本过高且依赖中心化的 CA
- IPFS 设计上希望能运行在各种网络上,所以并不想强依赖于 TLS 层的加密
IPFS 选择的方案是这样:
- 在节点创建的时候使用 S/Kademlia 提出的静态加密谜题(static crypto puzzle) 来生成出一对非对称密钥,
NodeId是公钥的 Hash 值。 - 在节点建立连接的时候,节点会交换并验证公钥,然后检查
hash(other.PublicKey) == other.NodeId,如果不通过,这个链接就会被断开。
这里有两个细节需要展开介绍一下:
其一,为什么是 S/Kademlia?
去中心化网络往往会面对这样两个问题:
- 日蚀攻击(Eclipse Attack):攻击者通过使节点从整个网络上消失,从而完全控制特定节点对信息的访问。
- 女巫攻击(Sybil attack):攻击者可以创建出众多伪装节点以控制网络控制权,拒绝响应,干扰查询等等。
S/Kademlia 通过设计出一套加密谜题,使得节点的 ID 不能自由选择(静态 Hash),并确保大量生成节点 ID 的复杂性(ID 生成有点像一个 PoW 算法,只不过生成难度小很多)。随后节点所有的通信都会先验证节点 ID 然后通过这个加密谜题生成出来的非对称密钥进行通信。IPFS 相信 S/Kademlia 能够很好的缓解这些问题(女巫攻击是无法被避免的)。
其次,NodeId 选用什么样的 Hash 算法?
显然的,Hash 算法的选择会影响 NodeId 的安全性和验证的效率。IPFS 为了避免被锁定在特定的 Hash 函数上,采用了自描述的格式,称之为 multihash,格式如下:
<function code><digest length><digest bytes>
其中 function code 是一个 uint64,每个取值对应一个 Hash 算法,这些算法都预置在同一个表中。
这种自描述的格式后来被广泛推广,形成了一组独立的项目:Multiformats,旗下包括 multihash, multiaddr, multicodec 等。
Network
IPFS 要求网络层提供如下功能:
- Transport(传输):能跑在 TCP / UDP 等多种协议基础上
- Reliability(可靠性):如果底层协议不支持可靠传输,那网络层能够保证可靠性
- Connectivity(链接性):能够实现 NAT 透传
- Integrity(完整性):能够检查消息的完整性
- Authenticity(认证):能够使用发送者的私钥来签名发出去的消息
为了能够满足以上要求,社区开发出了 libp2p,同样从 IPFS 中剥离出来,组成了独立的项目。
Routing
IPFS 使用基于 Coral 和 S/Kademlia 的 Distributed Sloppy Hash Table(DSHT)来协调和维护 P2P 系统中的元数据信息。
在介绍 DSHT 之前,我们首先简单的了解一下 DHT(Distributed Hash Table,分布式哈希表):
DHT 是一种能将哈希表分散在不同的节点上,并且能提供相应的方法来查找的算法,Kademlia (简称 Kad)就是最出名的 DHT 实现之一,我们常用的 eMule, BitTorrent 等软件就使用 Kad 作为文件信息检索协议。
Kad 有如下优势:
- 跳数少:在一个有 n 个节点的系统总搜索值时,Kad 仅需要访问 O(log(n)) 个节点
- 低开销:Kad 优化了向其他节点发送的控制信息的数量
Coral 在 Kad 的基础上做了一些扩展:
- 通过调整数据分布策略,优化了存储和带宽的开销
- 将
get_value(key)放宽为get_any_value(key),降低了热门节点的负载 - 增加了
clusters的概念,允许节点有限访问他们所在的集群,降低了查找的延迟
正如前面所提到的,S/Kademlia 是 Kad 在安全上的扩展:
- 设计出一套加密谜题并对消息做验证,缓解了安全问题
- 保障诚实的节点能够在存在大量对手的情况下也能获得较高的链接成功率
总的来说,IPFS 使用的 DSHT 面向全局提供了这样一套接口:
type IPFSRouting interface {
FindPeer(node NodeId)
// gets a particular peer’s network address
SetValue(key []bytes, value []bytes)
// stores a small metadata value in DHT
GetValue(key []bytes)
// retrieves small metadata value from DHT
ProvideValue(key Multihash)
// announces this node can serve a large value
FindValuePeers(key Multihash, min int)
// gets a number of peers serving a large value
}
特别的,当数据比较小(小于等于 1KB)的时候,IPFS 会将这个数据直接存在 DHST 网络中。
Exchange
IPFS 使用基于 BitTorrent 协议的变体:BitSwap 来交换数据。
BitTorrent 协议(国内通常叫做 BT)可能是世界上应用最为广泛的 P2P 数据交换协议了,BitTorrent 的交互流程如下(原图来自 @Azard):
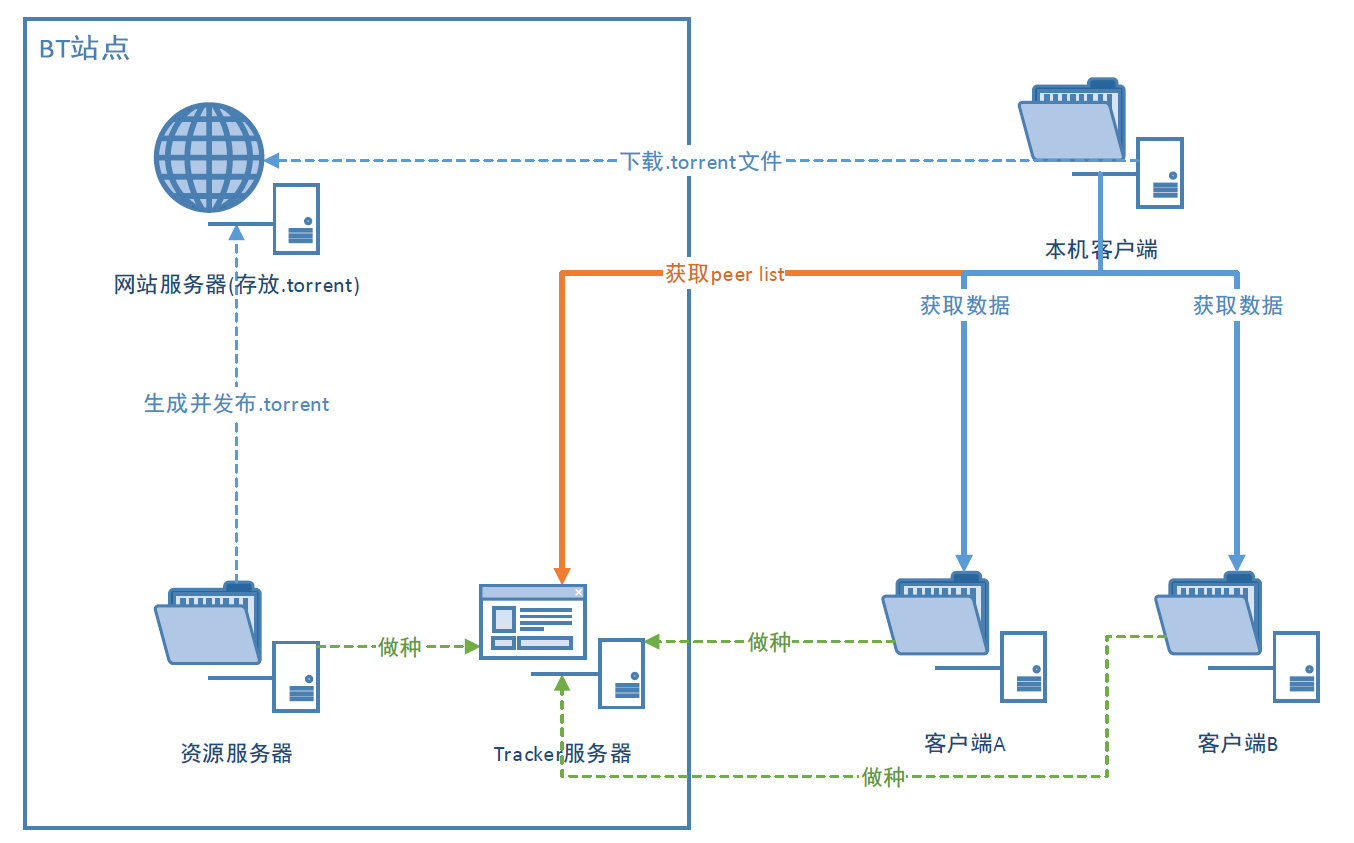
BitSwap 与 BitTorrent 一样,会维护 want_list(存储想要的 blocks)和 have_list(存储已有的 blocks)。区别在于 BitSwap 并不局限于单个 torrent 文件中的 block,而是从整个系统中获取 blocks,这些 blocks 甚至可能来自于完全不同的两个文件。经常使用 BT 下载的同学时常会有这样的烦恼:同样的文件对于不同的 Torrent 来说是独立的,假如更换了 PT 站或者种子,他们需要重新做种,将已有数据重新校验一次。而在 IPFS 网络中,这种问题就被彻底解决了,因为任意一个 Block 在整个系统中都是全局唯一的,只要节点中存在就能对外提供服务。
论文后续还用比较大的篇幅介绍了 BitSwap 如何激励节点上传,如何防止作弊以及 BitSwap 的具体流程,这里就不展开做介绍了。
Objects
IPFS 借鉴 Git 的思路,抽象出了 Object Merkle DAG。
在展开介绍 IPFS Object 之前,先来看一下 Merkle Tree (默克尔树,也叫做 Hash Tree)。Merkle Tree 看起来是这样(原图来自 @yeasy):
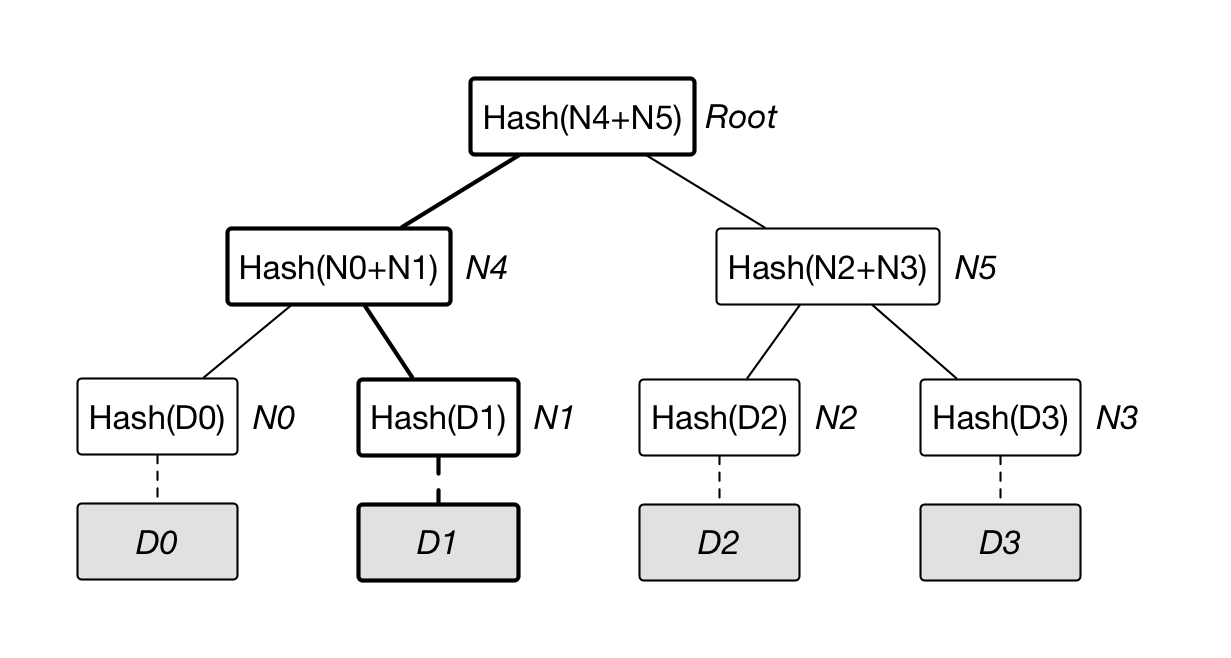
最底层的叶子节点是存储的数据,非叶子节点都是它孩子内容的哈希。不难看出,如果底层的数据发生了变化,那树根的值必定也会变化。不仅如此,在给定两颗 Merkle Tree 的情况下,我们还能够迅速的判别出底层的哪块数据发生了变化。IPFS 将 Merkle Tree 扩展为 Merkle DAG,不限制每个节点孩子的个数和整个树高度。
由这样的 Merkle DAG 构建而成的 Objects 拥有如下特性:
- 内容定位:所有内容都可以通过它的 mulithash 定位
- 抗破坏性:所有内容都可以通过它的 multihash 校验
- 去重:所有有着相同 multihash 的对象都存储且只存一份
IPFS Object 的结构如下:
type IPFSLink struct {
Name string
// name or alias of this link
Hash Multihash
// cryptographic hash of target
Size int
// total size of target
}
type IPFSObject struct {
links []IPFSLink
// array of links
data []byte
// opaque content data
}
通过 IPFSLink 和 IPFSObject,我们可以构建出一个类 UNIX 的 Path API:
> ipfs ls /XLZ1625Jjn7SubMDgEyeaynFuR84ginqvzb
XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x 189458 less
XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5 19441 script
XLF4hwVHsVuZ78FZK6fozf8Jj9WEURMbCX4 5286 template
<object multihash> <object size> <link name>
我们可以将任意 Object 作为根目录来访问数据,也可以直接通过数据的 multihash 来定位。以访问 <foo>/bar/baz 中的 baz 为例,我们有如下访问方式:
/ipfs/<hash-of-foo>/bar/baz/ipfs/<hash-of-bar>/baz/ipfs/<hash-of-baz>
IPFS 上的节点只会存储它感兴趣的内容,其他的内容在过期后就会被 GC。所以论文中还提出了 Object Pinning 的机制:允许用户手动 pin 一些 Object,将他们永久的保存在节点的本地存储中。
Files
上一节提到 IPFSLink 和 IPFSObject 可以构建出一个类 UNIX 的 Path API,但是这个太简陋了,不具备实用性。IPFS 在 Objects 抽象的基础上,抽象出一套基于 IPFS Objects 版本化文件系统模型:
- blob:一个变长的数据 block
- list:一组 block 或者其他的 list
- tree: 一组 block,list 或者其他的 tree
- commit: tree 版本历史中的一个快照
File Object: blob
blob 由独立的数据块构成,它没有链接:
{
"data": "some data here"
// blobs have no links
}
File Object: list
list 用来表示一个由若干 blob 组成的大文件,它的 data 是一个列表,内容是 links 对应的类型。它的 link 则与 data 中的顺序相对应,每个 Link 都没有 name。
{
"data": ["blob", "list", "blob"],
// lists have an array of object types as data
"links": [
{ "hash": "XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x", "size": 189458 },
{ "hash": "XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5", "size": 19441 },
{ "hash": "XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z", "size": 5286 }
// lists have no names in links
]
}
File Object: tree
tree 与 Git 中的 tree 类似,用来表示一个目录或者一个 Map,它不包含 data。
{
"data": nil,
// trees have no data, only links
"links": [
{ "hash": "XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x",
"name": "less", "size": 189458 },
{ "hash": "XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5",
"name": "script", "size": 19441 },
{ "hash": "XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z",
"name": "template", "size": 5286 }
// trees do have names
]
}
File Object: commit
commit 表示 IPFS 中任意对象的版本历史。
{
"data": {
"type": "tree",
"date": "2014-09-20 12:44:06Z",
"message": "This is a commit message."
},
"links": [
{ "hash": "XLa1qMBKiSEEDhojb9FFZ4tEvLf7FEQdhdU",
"name": "parent", "size": 25309 },
{ "hash": "XLGw74KAy9junbh28x7ccWov9inu1Vo7pnX",
"name": "object", "size": 5198 },
{ "hash": "XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm",
"name": "author", "size": 109 }
]
}
IPFS 没有规定一个文件该如何切块,只是提供一些建议,所以仍然存在两个完全一致的文件最终无法去重的问题。
Naming
上述讨论的所有协议构建出了一套 immutable file system,它很有效的解决了数据检索,数据完整性,缓存友好性等问题。但是对于真实的应用来说,mutable 仍然是一个很重要的特性。我们总是期望我们关注的博客能时不时的更新,而不是总是这些文章。换个角度来看就是,我们总是期望我能通过一个固定的地址来访问博客,而不是每次博客更新之后都要去找最新的链接。
IPFS 的论文提出了一个很好看的解决方案:
- 在身份的章节中我们就提到过:
NodeId = hash(node.PubKey) - 于是可以使用
NodeId作为 Namespace:/ipns/<NodeId> - 用户可以使用他自己的私钥在这个 namespace 下发布对象
- 当其他人访问时,只需要检查
hash(node.PublicKey) == node.NodeId即可
更进一步的,IPFS 可以复用现有的 DNS 机制:如果 /ipns/<domain> 是一个有效域名,那 IPFS 就会尝试去寻找这个域名以 ipns 为 key 的 TXT 记录:
ipfs.benet.ai. TXT "ipfs=XLF2ipQ4jD3U ..."
相当于执行了一次软链接:
ln -s /ipns/XLF2ipQ4jD3U /ipns/fs.benet.ai
这个过程在 通过 IPFS 分发文件 中有更完整的描述
分析
IPFS 可以说是 P2P 网络的集大成者,他融合了 Kademlia,BitTorrent,Git,SFS(Self-Certified Filesystems) 等众多设计的经验,成功的设计出一套去中心化的文件系统。但是它还是有这样几个缺点:
- IPFS 的节点激励不够,实际上这也是 BitTorrent / eMule 等系统中同样存在的问题,节点没有意愿去存储和分发别人的数据
- IPFS 数据持久性没有保证,与其说是文件系统,其实更像是一个分发系统,如果内容提供者自己不持续提供服务的话,这些数据最终会从网络中消失
Protocol Labs 也认识到了这样的问题,所以他们提出了基于 IPFS 协议的 Filecoin,尝试通过区块链的激励机制来鼓励各个节点存储数据,构建出一个去中心化的冷存储系统。业界也在探索如何将 IPFS 与 Filecoin 的特性结合起来充分运用,textile 的 powergate 是其中的一次尝试,它将 IPFS 视作热存储,将 Filecoin 视作冷存储,开发出了一套 multitiered file storage。
上面是业界公认的看法,下面是我个人的看法:
- IPFS 的文件切块算法是由客户端自由决定的,这有可能(没实际验证过)提高了整体的重复率
- IPFS 目前的文件模型设计可能会导致他对超大目录的支持能力不佳 (IPFS and Gentoo Portage (distfiles))
- IPFS 缺少了一个索引层,无法检索网络内存在的数据,降低了它的使用价值 (ipfs-search 是个不错的尝试,但是更想要一个去中心化的方案)
参考资料
- DHT 分布式哈希表 完整的介绍 DHT 相关技术
Kademlia来自于 Paper Kademlia:A Peer-to-peer Information System Based on the XOR MetricS/Kademlia来自于 Paper S/Kademlia: A practicable approach towards secure key-based routing- Coral 引入了 distributed sloppy hash table (DSHT) 抽象
- The BitTorrent Protocol Specification 是 BitTorrent 协议的规范
- 浅入浅出BitTorrent协议 比较深入的介绍了 BitTorrent 协议
- Merkle 树结构 提供了简单但是翔实的介绍